Cross-entropy is commonly used in machine learning as a loss function.
Cross-entropy is a measure from the field of information theory, building upon entropy and generally calculating the difference between two probabilities distributions.
It is closely related to but is different from KL divergence that calculates the relative entropy between two probability distributions, whereas cross-entropy can be thought to calculate the total entropy between the distributions.
Cross-entropy is also related to and often confused with logistic loss, call log loss. Although the two measures are derived from a difference source, when used as loss functions for classification models, both measures calculate the same quantity and can be used interchangeably.
In this tutorial, you will discover cross-entropy for machine learninng.
- What is Cross-Entropy?
- Difference between Cross-Entropy and KL Divergence
- How to Calculate Cross-Entropy
- Cross-Entropy are a Loss-Function
- Difference between Cross-Entropy and Log Loss
1. What is Cross-Entropy?
Cross-entropy is a measure of the difference between two probability distribution for a given random variable or set of events. Specifically, it builds upon the idea of entropy from information theory and calculates the average number or bits required to represent or transmit an event from one distribution compared to the other distribution.
The intuition for this definition comes if we consider a target or underlying probability distribution P and an approximation of the target Q, then the cross-entropy of Q from P is the number of additional bits to represent an event using Q instead of P. The cross-entropy between two probability distributions, such as Q from P, can be stated formally as:
H(P,Q).
Where H() is the cross-entropy function, P may be the target distribution and Q is the approximation of the target distribution. Cross-entropy can be calculated using the probabilities of the events from P and Q, as follows:

Where P (x) is the probability of the event x in P , Q(x) is the probability of event x in Q and log() is the base-2 logarithm, meaning that the results are in bits.
If the base-e or natural logarithm is used instead, the result will have the units called nats.
This calculation is for discrete probability distributions, although a similar calculation can be used for continuous probability distributions using the integral across the events instead of the sum.
The result will be a positive number measured in bits and will be equal to the entropy of the distribution if the two probability distributions are identical.
2. Difference between Cross-Entropy and KL Divergence
Cross-entropy is not KL Divergence. Cross-entropy is related to divergence measures, such as the Kullback-Leibler. KL Divergence that quantifies how much one distribution differs from another.
Specifically, the KL divergence measures a very similar quantity to cross-entropy.
It measures the average number of extra bits required to represent a message with Q instead of P, not the total number of bits.
As such, the KL divergence is often referred to as the relative entropy.
Cross-Entropy: Average number of total bits to represent an event from Q instead of P.
Relative Entropy (KL Divergence): Average number of extra bits to represent an event from Q instead of P.
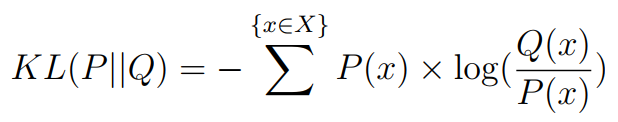

Where H(P,Q) is the cross-entropy of Q from P , H(P ) is the entropy of P and KL(P||Q) is the divergence of Q from P.
Like KL divergence, cross-entropy is not symmetrical, meaning that:
H(P,Q) # H(Q,P)
As we will see later, both cross-entropy and KL divergence calculate the same quantity when they are used as loss functions for optimizing a classification predictive model.
3. How to Calculate Cross-Entropy
A. Two Discrete Probability Distributions
Consider a random variable with three discrete events as different color: red, green and blue. We may have two difference probabilities distributions.
from matplotlib import pyplot
# define distributions
events = ['red', 'green', 'blue']
p = [0.10, 0.40, 0.50]
q = [0.80, 0.15, 0.05]
print('P=%.3f Q=%.3f' % (sum(p), sum(q)))
# plot first distribution
pyplot.subplot(2,1,1)
pyplot.bar(events, p)
# plot second distribution
pyplot.subplot(2,1,2)
pyplot.bar(events, q)
# show the plot
pyplot.show()
-----Result-----
 |
| Histogram of Two Different Probability Distributions for the Same Random Variable |
B. Calculate Cross-Entropy Between Distributions
# example of calculating cross-entropy
from math import log2
# calculate cross-entropy
def cross_entropy(p, q):
return -sum([p[i]*log2(q[i]) for i in range(len(p))])
# define data
p = [0.10, 0.40, 0.50]
q = [0.80, 0.15, 0.05]
# calculate cross-entropy H(P, Q)
ce_pq = cross_entropy(p, q)
print('H(P, Q): %.3f bits' % ce_pq)
# calculate cross-entropy H(Q, P)
ce_qp = cross_entropy(q, p)
print('H(Q, P): %.3f bits' % ce_qp)
from math import log2
# calculate cross-entropy
def cross_entropy(p, q):
return -sum([p[i]*log2(q[i]) for i in range(len(p))])
# define data
p = [0.10, 0.40, 0.50]
q = [0.80, 0.15, 0.05]
# calculate cross-entropy H(P, Q)
ce_pq = cross_entropy(p, q)
print('H(P, Q): %.3f bits' % ce_pq)
# calculate cross-entropy H(Q, P)
ce_qp = cross_entropy(q, p)
print('H(Q, P): %.3f bits' % ce_qp)
-----Result-----
H(P, Q): 3.288 bits
H(Q, P): 2.906 bits
H(Q, P): 2.906 bits
C. Calculate Cross-Entropy Between a Distribution and Itself
# example of calculating cross entropy for identical distributions
from math import log2
# calculate cross entropy
def cross_entropy(p, q):
return -sum([p[i]*log2(q[i]) for i in range(len(p))])
# define data
p = [0.10, 0.40, 0.50]
q = [0.80, 0.15, 0.05]
# calculate cross entropy H(P, P)
ce_pp = cross_entropy(p, p)
print('H(P, P): %.3f bits' % ce_pp)
# calculate cross entropy H(Q, Q)
ce_qq = cross_entropy(q, q)
print('H(Q, Q): %.3f bits' % ce_qq)
from math import log2
# calculate cross entropy
def cross_entropy(p, q):
return -sum([p[i]*log2(q[i]) for i in range(len(p))])
# define data
p = [0.10, 0.40, 0.50]
q = [0.80, 0.15, 0.05]
# calculate cross entropy H(P, P)
ce_pp = cross_entropy(p, p)
print('H(P, P): %.3f bits' % ce_pp)
# calculate cross entropy H(Q, Q)
ce_qq = cross_entropy(q, q)
print('H(Q, Q): %.3f bits' % ce_qq)
-----Result-----
H(P, P): 1.361 bits
H(Q, Q): 0.884 bits
H(Q, Q): 0.884 bits
D. Calculate Cross-Entropy Using KL Divergence
# example of calculating cross-entropy with kl divergence
from math import log2
# calculate the kl divergence KL(P || Q)
def kl_divergence(p, q):
return sum(p[i] * log2(p[i]/q[i]) for i in range(len(p)))
# calculate entropy H(P)
def entropy(p):
return -sum([p[i] * log2(p[i]) for i in range(len(p))])
# calculate cross-entropy H(P, Q)
def cross_entropy(p, q):
return entropy(p) + kl_divergence(p, q)
# define data
p = [0.10, 0.40, 0.50]
q = [0.80, 0.15, 0.05]
# calculate H(P)
en_p = entropy(p)
print('H(P): %.3f bits' % en_p)
# calculate kl divergence KL(P || Q)
kl_pq = kl_divergence(p, q)
print('KL(P || Q): %.3f bits' % kl_pq)
# calculate cross-entropy H(P, Q)
ce_pq = cross_entropy(p, q)
print('H(P, Q): %.3f bits' % ce_pq)
from math import log2
# calculate the kl divergence KL(P || Q)
def kl_divergence(p, q):
return sum(p[i] * log2(p[i]/q[i]) for i in range(len(p)))
# calculate entropy H(P)
def entropy(p):
return -sum([p[i] * log2(p[i]) for i in range(len(p))])
# calculate cross-entropy H(P, Q)
def cross_entropy(p, q):
return entropy(p) + kl_divergence(p, q)
# define data
p = [0.10, 0.40, 0.50]
q = [0.80, 0.15, 0.05]
# calculate H(P)
en_p = entropy(p)
print('H(P): %.3f bits' % en_p)
# calculate kl divergence KL(P || Q)
kl_pq = kl_divergence(p, q)
print('KL(P || Q): %.3f bits' % kl_pq)
# calculate cross-entropy H(P, Q)
ce_pq = cross_entropy(p, q)
print('H(P, Q): %.3f bits' % ce_pq)
-----Result-----
H(P): 1.361 bits
KL(P || Q): 1.927 bits
H(P, Q): 3.288 bits
KL(P || Q): 1.927 bits
H(P, Q): 3.288 bits
4. Cross-Entropy as a Loss Function
Cross-entropy is widely used as a loss function when optimizing classification models.
Two examples that you may encounter include the logistic regression algorithm, and artificial neural networks that can be used for classification tasks.
Binary Classification: Task of predicting one of two class labels for a given example.
Multiclass Classification: Task of predicting one of more than two class labels for a given example.
Expected Probability (y): The known probability of each class label for an example in the dataset (P).
Predicted Probability (yhat): The probability of each class label an example predicted by the model (Q).
We can, therefore, estimate the cross-entropy for a single prediction using cross-entropy calculation described above, for example:

Where each x belong to X is a class label that could be assigned to the example, and P(x) will be 1 for the known label and 0 for all other labels. The cross-entropy for a single example in a binary classification task can be stated by unrolling the sum operation as following:
H(P,Q) = -(P(class0) × log(Q(class0)) + P(class1) × log(Q(class1)))
Predicted P(class0) = 1 - yhat
Predicted P(class1) = yhat
A. Calculate Entropy for Class Labels
# entropy of examples from a classification task with 3 classes
from math import log2
from numpy import asarray
# calculate entropy
def entropy(p):
return -sum([p[i] * log2(p[i]) for i in range(len(p))])
# class 1
p = asarray([1,0,0]) + 1e-15
print(entropy(p))
# class 2
p = asarray([0,1,0]) + 1e-15
print(entropy(p))
# class 3
p = asarray([0,0,1]) + 1e-15
print(entropy(p))
from math import log2
from numpy import asarray
# calculate entropy
def entropy(p):
return -sum([p[i] * log2(p[i]) for i in range(len(p))])
# class 1
p = asarray([1,0,0]) + 1e-15
print(entropy(p))
# class 2
p = asarray([0,1,0]) + 1e-15
print(entropy(p))
# class 3
p = asarray([0,0,1]) + 1e-15
print(entropy(p))
-----Result-----
9.805612959471341e-14
9.805612959471341e-14
9.805612959471341e-14
9.805612959471341e-14
9.805612959471341e-14
B. Cross-Entropy Between Class Labels and Probabilities
Binary Cross-Entropy: Cross-entropy as a loss function for a binary classification task
Categorical Cross-Entropy: Cross-entropy as a loss function for a multiclass classification task
# calculate cross entropy for classification problem
from math import log
from numpy import mean
# calculate cross entropy
def cross_entropy(p, q):
return -sum([p[i]*log(q[i]) for i in range(len(p))])
# define classification data
p = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
q = [0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3]
# calculate cross entropy for each example
results = list()
for i in range(len(p)):
# create the distribution for each event {0, 1}
expected = [1.0 - p[i], p[i]]
predicted = [1.0 - q[i], q[i]]
# calculate cross entropy for the two events
ce = cross_entropy(expected, predicted)
print('>[y=%.1f, yhat=%.1f] ce: %.3f nats' % (p[i], q[i], ce))
results.append(ce)
# calculate the average cross entropy
mean_ce = mean(results)
print('Average Cross Entropy: %.3f nats' % mean_ce)
from math import log
from numpy import mean
# calculate cross entropy
def cross_entropy(p, q):
return -sum([p[i]*log(q[i]) for i in range(len(p))])
# define classification data
p = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
q = [0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3]
# calculate cross entropy for each example
results = list()
for i in range(len(p)):
# create the distribution for each event {0, 1}
expected = [1.0 - p[i], p[i]]
predicted = [1.0 - q[i], q[i]]
# calculate cross entropy for the two events
ce = cross_entropy(expected, predicted)
print('>[y=%.1f, yhat=%.1f] ce: %.3f nats' % (p[i], q[i], ce))
results.append(ce)
# calculate the average cross entropy
mean_ce = mean(results)
print('Average Cross Entropy: %.3f nats' % mean_ce)
-----Result-----
>[y=1.0, yhat=0.8] ce: 0.223 nats
>[y=1.0, yhat=0.9] ce: 0.105 nats
>[y=1.0, yhat=0.9] ce: 0.105 nats
>[y=1.0, yhat=0.6] ce: 0.511 nats
>[y=1.0, yhat=0.8] ce: 0.223 nats
>[y=0.0, yhat=0.1] ce: 0.105 nats
>[y=0.0, yhat=0.4] ce: 0.511 nats
>[y=0.0, yhat=0.2] ce: 0.223 nats
>[y=0.0, yhat=0.1] ce: 0.105 nats
>[y=1.0, yhat=0.9] ce: 0.105 nats
>[y=1.0, yhat=0.9] ce: 0.105 nats
>[y=1.0, yhat=0.6] ce: 0.511 nats
>[y=1.0, yhat=0.8] ce: 0.223 nats
>[y=0.0, yhat=0.1] ce: 0.105 nats
>[y=0.0, yhat=0.4] ce: 0.511 nats
>[y=0.0, yhat=0.2] ce: 0.223 nats
>[y=0.0, yhat=0.1] ce: 0.105 nats
>[y=0.0, yhat=0.3] ce: 0.357 nats
Average Cross Entropy: 0.247 nats
Average Cross Entropy: 0.247 nats
C. Calculate Cross-Entropy Using Keras
# calculate cross entropy with keras
from numpy import asarray
from keras import backend
from keras.losses import binary_crossentropy
# prepare classification data
p = asarray([1, 1, 1, 1, 1, 0, 0, 0, 0, 0])
q = asarray([0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3])
# convert to keras variables
y_true = backend.variable(p)
y_pred = backend.variable(q)
# calculate the average cross-entropy
mean_ce = backend.eval(binary_crossentropy(y_true, y_pred))
print('Average Cross Entropy: %.3f nats' % mean_ce)
from numpy import asarray
from keras import backend
from keras.losses import binary_crossentropy
# prepare classification data
p = asarray([1, 1, 1, 1, 1, 0, 0, 0, 0, 0])
q = asarray([0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3])
# convert to keras variables
y_true = backend.variable(p)
y_pred = backend.variable(q)
# calculate the average cross-entropy
mean_ce = backend.eval(binary_crossentropy(y_true, y_pred))
print('Average Cross Entropy: %.3f nats' % mean_ce)
-----Result-----
Average Cross Entropy: 0.247 nats
5. Difference Between Cross-Entropy and Log Loss
Cross-Entropy is not Log Loss, but they calculate the same quantity when used as loss functions for binary classification problems.
A. Log Loss is the Negative Log Likelihood
Logistic loss refers to the loss function commonly used to optimize a logistic regression model. It may also be referred to as logarithmic loss or simply log loss.
Many models are optimized under a probabilistic framework called maximum likelihood estimation, or MLE, that involves finding a set of parameters that best explain the observed data.
This involves selecting a likelihood function that defines how likely a set of observations (data) are given model parameters. When a log likelihood function is used, it if often referred to as optimizing the log likelihood for the model. Because it is more common to minimize a function than to maximize it in practice, the log likelihood function is inverted by adding a negative sign to the front. This transforms it into a Negative Log Likelihood function (NLL). It deriving the log likelihood function under a framework of MLE for a Bernoulli probability distribution functions (two classes), the calculation comes out to be:
This quantity can averaged over all training examples by calculating the average of the log the likelihood function.
Negative log-likelihood for binary classification problems is often shortened to simply log loss as the loss function derived for logistic regression.
log loss = negative log-likelihood, under a Bernoulli probability distribution
We can see that the negative log-likelihood is the same calculation as is used for the cross-entropy for Bernoulli probability distribution functions (two events or classes).
In fact, the negative log-likelihood for Multinoulli distributions (multiclass classification) also matches the calculation for cross-entropy.
B. Log Loss and Cross Entropy Calculate the Same Thing
For binary classification problems, log loss, cross-entropy and negative log-likelihood are used interchangeably.
More generally, the terms cross-entropy and negative log-likelihood are used interchangeably in the context of loss functions for classification models.
Therefore, calculating log loss will give the same quantity as calculating the cross-entropy for Bernoulli probability distribution.
We can confirm this by calculating the log loss using the log_loss() function from the scikit-learn API.
Calculating the average log loss on the same set of actual and predicted probabilities from the previous section should give the same result as calculating the average cross-entropy.
# calculate log loss for classification problem with scikit-learn
from sklearn.metrics import log_loss
from numpy import asarray
# define classification data
p = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
q = [0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3]
# define data as expected, e.g. probability for each event {0, 1}
y_true = asarray([[1-v, v] for v in p])
y_pred = asarray([[1-v, v] for v in q])
# calculate the average log loss
ll = log_loss(y_true, y_pred)
print('Average Log Loss: %.3f' % ll)
from sklearn.metrics import log_loss
from numpy import asarray
# define classification data
p = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
q = [0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3]
# define data as expected, e.g. probability for each event {0, 1}
y_true = asarray([[1-v, v] for v in p])
y_pred = asarray([[1-v, v] for v in q])
# calculate the average log loss
ll = log_loss(y_true, y_pred)
print('Average Log Loss: %.3f' % ll)
-----Result-----
Average Log Loss: 0.247
This does not mean that log loss calculates cross-entropy or cross-entropy calculates log loss.
Instead, they are different quantities, arrived at from different fields of study, that under the conditions of calculating a loss function for a classification task, result in an equivalent calculation and result.
Specifically, a cross-entropy loss function is equivalent to a maximum likelihood function under a Bernoulli or Multinoulli probability distribution.
This demonstrates a connection between the study of maximum likelihood estimation and information theory for discrete probability distributions.
It is not limited to discrete probability distributions, and this fact is surprising to many practitioners that hear it for the first time.
No comments:
Post a Comment